This is a question I had in my mind for a while. I was very interested to know how document-sharing websites work in general and if it is possible to build one using .Net and other free and open source technologies.
After spending one Internet, readay searching through dig bnlogs and forums I came to the conclusion that it is possible! At least in theory it is possible.
What websites like Scribd do is that they allow their users to upload documents in various formats, then this documents will be shown in a control that is implemented using Adobe Flash. So they convert documents from various formats to Adobe Flash but how they do it and what goes on behind the scene?
I will try to explain different steps of the process and show you with which tool you can do the same with .Net. Just before we start this is not something official about how Scribd or any other websites of this type work, this is only how I think they work and how it is possible to do the same.
Step 1: Convert documents from various formats to PDF
OpenOffice supports various formats (including Microsoft Office formats) and it can export them to PDF format which is what we need.
So we have the tool but how to call it from our code. Luckily there is a great article in CodeProject which solves this problem in an elegant way. This article provides solution alongside the necessary code to easily call OpenOffice to convert documents to PDF format.
Step 2: Index document contents to be able to search through them
Another aspect of document-sharing sites is search. They allow their users to search for documents using keywords. They store hundreds of thousands of documents so having a proficient searching mechanism is very important.
To index documents we need to extract text from the documents. In first step we convert all documents to PDF, so we need to find a way to extract text from PDF files. One way to do this is to use the IFilter interface which was designed by Microsoft for use in its Indexing Service. You can find a great article in CodeProject named Using IFilter in C# which describes how you can use them to extract text from various document formats (which PDF is one of them).
After extracting text we need a tool for index the extracted text and also be able to search through this index in a proficient way. I have been using Lucene.Net which is a port of famous Lucene library for a while and I can say it is amazingly fast and also easy to use. Lucene.Net is exactly what we want here. It has all the necessary features to index the extracted text from documents and search through them very fast.
Step 3: Create thumbnails for the documents
This may look unnecessary but all of document-sharing websites have it and I think it's cool. There are commercial libraries for .Net that allow you to create an image from pages of a PDF document. But we are looking for a free solution here so using commercial components is not an option.
Ghostscript has the ability to raster PDF files. What we need is a .Net wrapper that can call it. There are many implementations that can be easily found by doing a simple search using your favorite search engine. GhostscriptSharp is one of them.
Step4: Convert the PDF files to Adobe Flash
SWFTools is a collection of utilities which one of them is PDF2SWF. PDF2SWF is a command line utility which simply converts your PDF to SWF. I couldn't find a .Net wrapper for this utility but calling a command line program from .Net is very easy.
After the conversion is done we get a SWF file of our PDF that simply is a collection of pages with no navigation. PDF2SWF provides the option to combine a simple navigation UI with the generated SWF but I think it would be better to use a more advanced viewer like SWF Document Viewer and customize it based on your needs.
Conclusion
I think the answer to this article title is yes and we can build such a website. I have not tried to do so but it seems we have all the tools necessary to do so.
I would be glad to hear your thoughts about this and if anyone has tried this approach. I would also like to hear about alternate ways of doing each step in the process.
23 Jan 2009
I use ASP.NET GridView in my projects a lot. It is a great control with powerful functionality that can be customized in many ways. GridView has many settings that you can use to alter its look and also offers you some predefined formats that you can use (you can access them by clicking Auto Format link on the bottom of GridView properties panel). What formats do is to modify different styling properties of the GridView such as row style, alternate row style, header style and so on.
What is the problem?
Modifying different styling properties of the GridView control to create a custom look may be simple but has a few problems. The biggest problem is the styling information will be included in the generated html and that causes the resulting page size to be bigger. Another problem is that you have to modify a lot of properties to find a look that satisfies you. Also later if you want to do a change in the look of GridView you have to modify all instances of the controls in your website.
The Solution
The good news is that you can use CSS to control the look of the GridView easily. You will add a few hooks to the GridView control and you are ready to write some CSS to completely change the look of the control.
Source code for this article can be accessed from github.com/atashbahar/gridview-makeover.
Modifying GridView look is very easy using CSS. By spending a little time you can create really cool styles that can reuse in your projects easily. Following picture is a screen shot of the final result of this article.
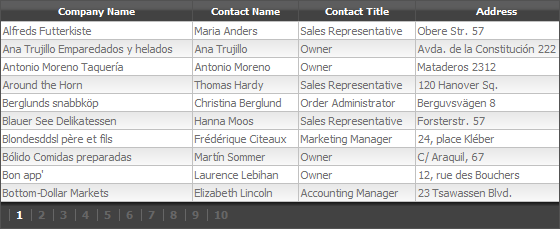
Implementation
Here's the GridView control syntax in our ASP.NET page. The only properties that we need to change to provide the custom look are CssClass, PagerStyle-CssClass and AlternatingRowStyle-CssClass.
<asp:GridView ID="gvCustomres" runat="server"
DataSourceID="customresDataSource"
AutoGenerateColumns="False"
GridLines="None"
AllowPaging="true"
CssClass="mGrid"
PagerStyle-CssClass="pgr"
AlternatingRowStyle-CssClass="alt">
<Columns>
<asp:BoundField DataField="CompanyName" HeaderText="Company Name" />
<asp:BoundField DataField="ContactName" HeaderText="Contact Name" />
<asp:BoundField DataField="ContactTitle" HeaderText="Contact Title" />
<asp:BoundField DataField="Address" HeaderText="Address" />
<asp:BoundField DataField="City" HeaderText="City" />
<asp:BoundField DataField="Country" HeaderText="Country" />
</Columns>
</asp:GridView>
<asp:XmlDataSource ID="customresDataSource" runat="server" DataFile="~/App_Data/data.xml"></asp:XmlDataSource>
The CSS to provide the custom look is very short and you can change the view and create new looks really easy.
.mGrid {
width: 100%;
background-color: #fff;
margin: 5px 0 10px 0;
border: solid 1px #525252;
border-collapse:collapse;
}
.mGrid td {
padding: 2px;
border: solid 1px #c1c1c1;
color: #717171;
}
.mGrid th {
padding: 4px 2px;
color: #fff;
background: #424242 url(grd_head.png) repeat-x top;
border-left: solid 1px #525252;
font-size: 0.9em;
}
.mGrid .alt { background: #fcfcfc url(grd_alt.png) repeat-x top; }
.mGrid .pgr { background: #424242 url(grd_pgr.png) repeat-x top; }
.mGrid .pgr table { margin: 5px 0; }
.mGrid .pgr td {
border-width: 0;
padding: 0 6px;
border-left: solid 1px #666;
font-weight: bold;
color: #fff;
line-height: 12px;
}
.mGrid .pgr a { color: #666; text-decoration: none; }
.mGrid .pgr a:hover { color: #000; text-decoration: none; }
I have used three images for header, alternate rows and pager to create a more appealing look. There images are tiled horizontally using CSS to fit the whole row. You can find the images in the sample website code.

Conclusion
Creating custom looks for GridView control is very easy. You can create a completely different look using only a few lines of CSS. You can use the same CSS style for all GridView controls in your project and later if you want to change the look you can do it from one location in your style sheet file.
18 Jan 2009
Websites are getting more interactive these days and most of this interactivity comes from JavaScript. People are using different JavaScript libraries and frameworks to make their websites more interactive and user friendly.
What is the problem?
After a while you end up referencing to more than a few JavaScript files in your page and that causes a problem! Your pages will load slower; this happens for two reasons:
- You have used too much JavaScript. Total size of JavaScript files in some websites may reach more than 500KB and that's a lot, especially for users with slow connections. The best solution to this problem is to use gzip to compress JavaScript files as we do later in this article.
- JavaScript files are loaded one by one after each other by the browser. As you know there is a response time for each request that varies depending on your connection speed and your distance from the server. If you have many JavaScript files in your page these times are added together and cause a big delay when loading a page. I have tried to show this using Firebug (A very popular and necessary FireFox extension for web developers) in the following screenshot.
This is not the case for CSS or image files .If you reference multiple CSS files or images in your page they are loaded together by the browser.
The best solution to this problem is to combine JavaScript files into one big file to remove the delay caused when loading multiple JavaScript files one by one.
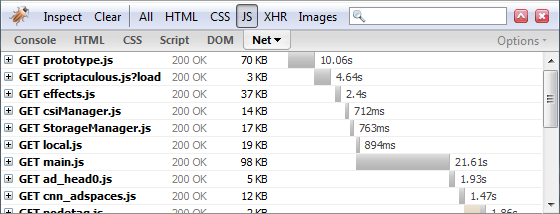
What can we do?
The answer is simple! Combine the files and gzip the response. Actually we are going to take few extra steps to create something more useful and reusable. But how we are going to do that?
The easiest way to do this is to use an HTTP Handler that combines JavaScript files and compresses the response. So instead of referencing multiple JavaScript files in our pages we reference this handler like this:
<script type="text/javascript" src="ScriptCombiner.axd?s=Site_Scripts&v=1"></script>
ScriptCombiner.axd is our HTTP Handler here. Two parameters are passed to the handler, s and v. s stands for set name and v stands for version. When you make a change in your scripts you need to increase the version so browsers will load the new version not the cached one.
Set Name indicates list of JavaScript files that are processed by this handler. We save the list in a text file inside App_Data folder. The file contains relative paths to JavaScript files that need to be combined. Here is what Site_Scripts.txt file content should look like:
~/Scripts/ScriptFile1.js
~/Scripts/ScriptFile2.js
Most of work is done inside the HTTP Handler; I try to summarize what happens in the handler:
- Load the list of paths JavaScript files from the text files specified by the set name.
- Read the content of each file and combine them into one big string that contains all the JavaScript.
- Call Minifier to remove comments and white spaces from the combined JavaScript string.
- Use gzip to compress the result into a smaller size.
- Cache the result for later references so we don't have to do all the processing for each request.
We also take few extra steps to make referencing this handler easier. Source code for this article can be accessed from github.com/atashbahar/script-combiner.
Here is a screenshot of the website opened in solution explorer so you get a better idea of how file are organized in the sample website.
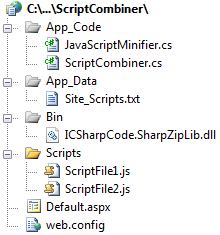
The implementation
I have got most of the code for the handler from Omar Al Zabir article named "HTTP Handler to Combine Multiple Files, Cache and Deliver Compressed Output for Faster Page Load" so most of the credit goes to him.
HTTP Handler contains a few helper methods that their purpose is very clear. I try to describe each shortly.
CanGZip method checks if the browser can support gzip and returns true in that case.
private bool CanGZip(HttpRequest request)
{
string acceptEncoding = request.Headers["Accept-Encoding"];
if (!string.IsNullOrEmpty(acceptEncoding) &&
(acceptEncoding.Contains("gzip") || acceptEncoding.Contains("deflate")))
return true;
return false;
}
WriteBytes writes the combined and compresses bytes to the response output. We need to set different content type for response based on if we support gzip or not. The other important part of this method sets the caching policy for the response which tells the browser to cache the response for CACHE_DURATION amount of time.
private void WriteBytes(byte[] bytes, bool isCompressed)
{
HttpResponse response = context.Response;
response.AppendHeader("Content-Length", bytes.Length.ToString());
response.ContentType = "application/x-javascript";
if (isCompressed)
response.AppendHeader("Content-Encoding", "gzip");
else
response.AppendHeader("Content-Encoding", "utf-8");
context.Response.Cache.SetCacheability(HttpCacheability.Public);
context.Response.Cache.SetExpires(DateTime.Now.Add(CACHE_DURATION));
context.Response.Cache.SetMaxAge(CACHE_DURATION);
response.ContentEncoding = Encoding.Unicode;
response.OutputStream.Write(bytes, 0, bytes.Length);
response.Flush();
}
WriteFromCache checks if we have the combined script cached in memory, if so we write it to response and return true.
private bool WriteFromCache(string setName, string version, bool isCompressed)
{
byte[] responseBytes = context.Cache[GetCacheKey(setName, version, isCompressed)] as byte[];
if (responseBytes == null || responseBytes.Length == 0)
return false;
this.WriteBytes(responseBytes, isCompressed);
return true;
}
But most of the work is done inside ProcessRequest method. First we take a look at the method and I will try to explain important parts.
public void ProcessRequest(HttpContext context)
{
this.context = context;
HttpRequest request = context.Request;
// Read setName, version from query string
string setName = request["s"] ?? string.Empty;
string version = request["v"] ?? string.Empty;
// Decide if browser supports compressed response
bool isCompressed = this.CanGZip(context.Request);
// If the set has already been cached, write the response directly from
// cache. Otherwise generate the response and cache it
if (!this.WriteFromCache(setName, version, isCompressed))
{
using (MemoryStream memoryStream = new MemoryStream(8092))
{
// Decide regular stream or gzip stream based on whether the response can be compressed or not
using (Stream writer = isCompressed ? (Stream)(new ICSharpCode.SharpZipLib.GZip.GZipOutputStream(memoryStream)) : memoryStream)
{
// Read the files into one big string
StringBuilder allScripts = new StringBuilder();
foreach (string fileName in GetScriptFileNames(setName))
allScripts.Append(File.ReadAllText(context.Server.MapPath(fileName)));
// Minify the combined script files and remove comments and white spaces
var minifier = new JavaScriptMinifier();
string minified = minifier.Minify(allScripts.ToString());
// Send minfied string to output stream
byte[] bts = Encoding.UTF8.GetBytes(minified);
writer.Write(bts, 0, bts.Length);
}
// Cache the combined response so that it can be directly written
// in subsequent calls
byte[] responseBytes = memoryStream.ToArray();
context.Cache.Insert(GetCacheKey(setName, version, isCompressed),
responseBytes, null, System.Web.Caching.Cache.NoAbsoluteExpiration,
CACHE_DURATION);
// Generate the response
this.WriteBytes(responseBytes, isCompressed);
}
}
}
this.WriteFromCache(setName, version, isCompressed) returns true if we have the response cached in memory. It actually writes the data from cache to the response and returns true so we don't need to take any extra steps.
MemoryStream is used to hold compressed bytes in the memory. In case that browser does not support gzip no compression is done over bytes.
We use SharpZipLib to do the compression. This free library does gzip compression slightly better than .NET. You can easily use .NET compression by replacing line 20 with the following code:
using (Stream writer = isCompressed ? (Stream)(new GZipStream(memoryStream, CompressionMode.Compress)) : memoryStream)
GetScriptFileNames is a static method that returns a string array of JavaScript file paths in the set name. We will use this method for another purpose that we discuss it later.
JavaScriptMinifier class holds the code for Douglas Crockford JavaScript Minfier. Minifer removes comments and white spaces from JavaScript and results in a smaller size. You can download the latest version from http://www.crockford.com/javascript/jsmin.html.
After we wrote minified and compressed scripts to MemoryStream we insert them into cache so we don't need to take all these steps for each request. And finally we write the compressed bytes to the response.
Make it a little better
We can take one extra step to make the whole process a little better an easier to use. We can add a static method to our handler that generates JavaScript reference tag. We can make this even better by doing different actions when application is running in debug or release mode. In debug mode we usually don't want to combine our JavaScript files to track error easier, so we output reference to original files and generate all JavaScript references as if we have included in our page manually.
public static string GetScriptTags(string setName, int version)
{
string result = null;
#if (DEBUG)
foreach (string fileName in GetScriptFileNames(setName))
{
result += String.Format("\n<script type=\"text/javascript\" src=\"{0}?v={1}\"></script>", VirtualPathUtility.ToAbsolute(fileName), version);
}
#else
result += String.Format("<script type=\"text/javascript\" src=\"ScriptCombiner.axd?s={0}&v={1}\"></script>", setName, version);
#endif
return result;
}
GetScriptFileNames as described before returns an array of file names for a specified set.
// private helper method that return an array of file names inside the text file stored in App_Data folder
private static string[] GetScriptFileNames(string setName)
{
var scripts = new System.Collections.Generic.List<string>();
string setPath = HttpContext.Current.Server.MapPath(String.Format("~/App_Data/{0}.txt", setName));
using (var setDefinition = File.OpenText(setPath))
{
string fileName = null;
while (setDefinition.Peek() >= 0)
{
fileName = setDefinition.ReadLine();
if (!String.IsNullOrEmpty(fileName))
scripts.Add(fileName);
}
}
return scripts.ToArray();
}
<%= ScriptCombiner.GetScriptTags("Site_Scripts", 1) %>
So whenever we want to reference a handler in an ASP.NET page we only need to add the following tag inside the head section of our page:
There is a final step you need to take before making all this work. You need to add HTTP Handler to Web.config of your website. To do so make the following changes to your web.config file:
<configuration>
<system.web>
<httpHandlers>
<add verb="POST,GET" path="ScriptCombiner.axd" type="ScriptCombiner, App_Code"/>
</httpHandlers>
</system.web>
<!-- IIS 7.0 only -->
<system.webServer>
<handlers>
<add name="ScriptCombiner" verb="POST,GET" path="ScriptCombiner.axd" preCondition="integratedMode" type="ScriptCombiner, App_Code"/>
</handlers>
</system.webServer>
</configuration>
Conclusion
If you search the Internet you will find many similar methods. I have tried to combine the best parts of them to make something more useful. I hope you have enjoyed it.